Generation speed (tokens/s) on Llama3-8B with EAGLE-3, SEAGLE, and Vanilla for an 5k-token context size
Introduction
Speculative decoding is one of the most promising techniques for accelerating Large Language Model (LLM) inference, offering potential speedups of 2-4x while not altering the output (lossless). However, speculative decoding still struggles to achieve widespread adoption in production systems, due to a variety of factors.
EAGLE-3 is one of the most efficient speculative decoding models available today, but it's trained on a fixed context length of 2048 tokens. Beyond that threshold, accuracy drops and performance often collapses. This makes EAGLE-3 impractical for many real-world workloads such as RAG pipelines or coding assistants, which very often require larger context sizes.
In this blog post, we introduce SEAGLE (standing for Streaming-EAGLE), a novel approach that extends EAGLE-3's speculative decoding performance on 10x larger context sizes (we tested up to 30k tokens so far). Our method maintains the acceleration benefits of speculative decoding while achieving constant memory overhead regardless of sequence length. The results: the same 2-4x inference acceleration, but now scalable to wider applications in production.
Part 1: EAGLE-3 Speculative Decoding - Limitations
What is Speculative Decoding?
One of the main speed limitations of current LLMs is the inability to generate more than one token at once during the decode phase; this comes from the LLM being autoregressive. These decode steps require a lot of memory bandwidth, which limits the generation speed even when more compute capacity is available. One possible solution to use more of this compute capacity is to batch several requests, but that only improves the efficiency of the system, while slightly reducing the generation speed of individual requests.
So, how can we use some of the underutilized compute capacity to improve the generation speed?
One solution is speculative decoding. While we can't generate several tokens at once, but given some probable next tokens as an input, we can verify them all at once in parallel!
In order to obtain the next tokens, we use a fast and lightweight model.
During the verification phase, if a token is validated it is kept. If it is not validated it is discarded alongside all the next ones, and the target model keeps the correct token it found instead of the draft input.
Speculative decoding principle illustration, from NVIDIA Technical Blog
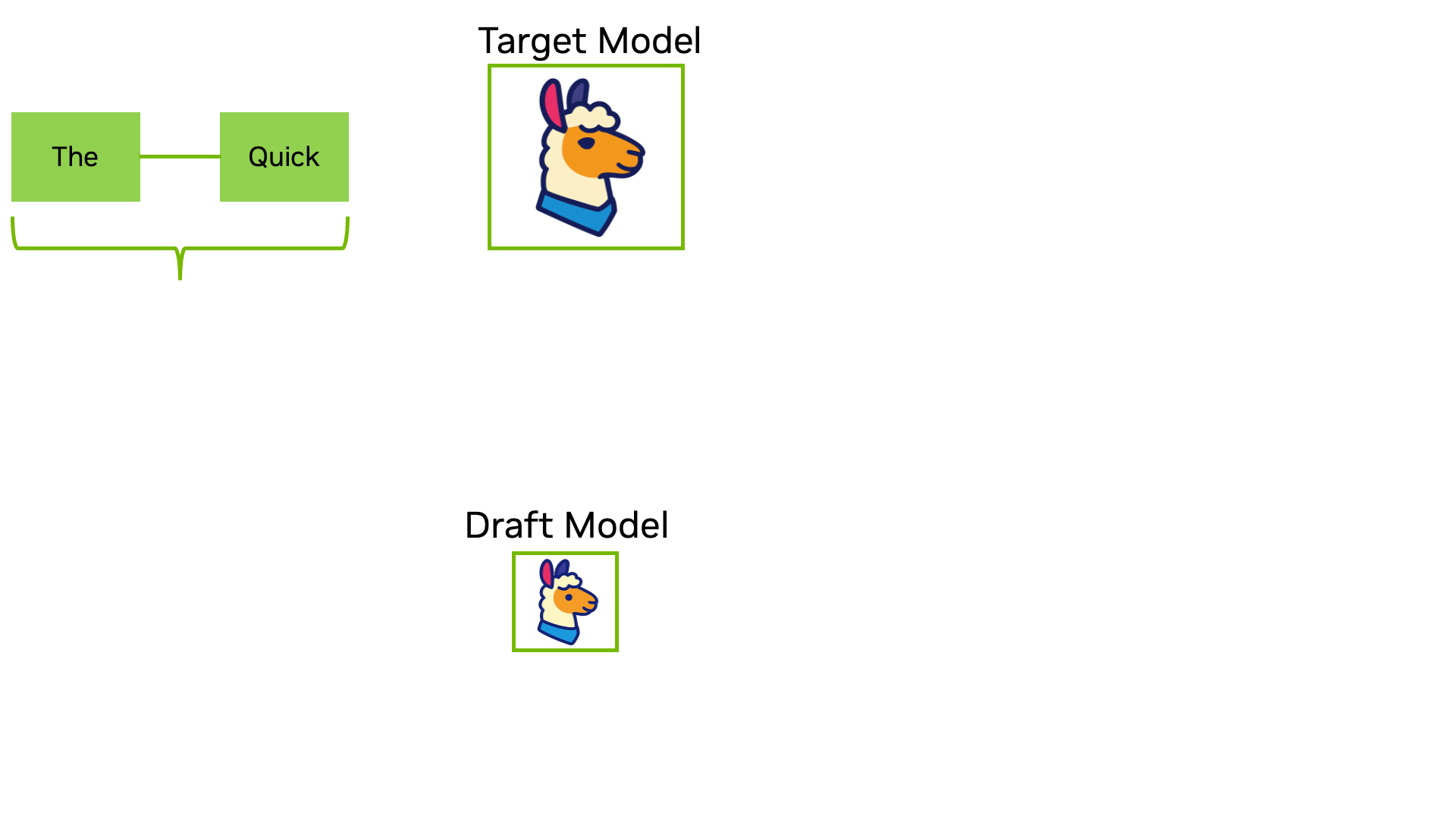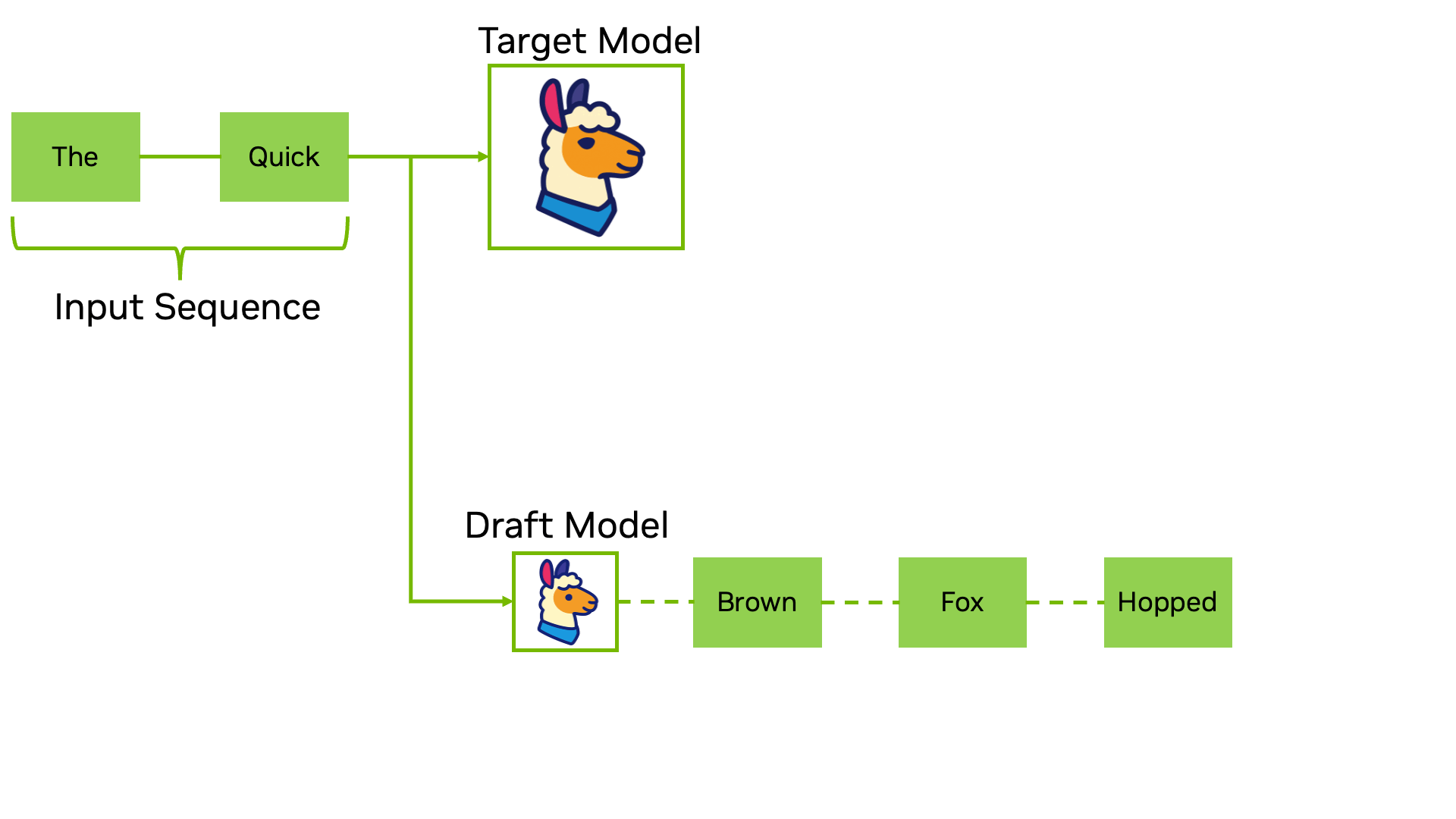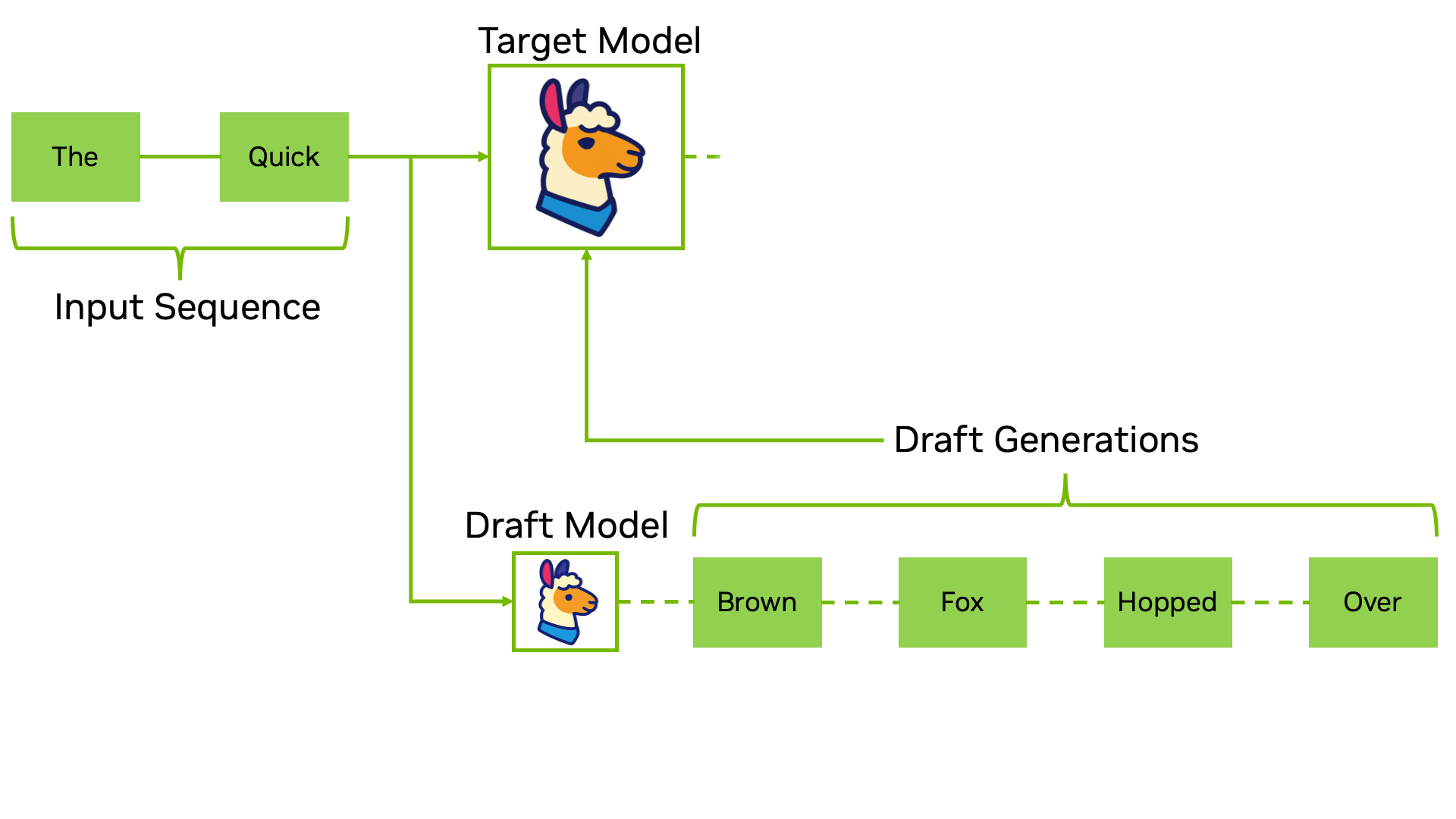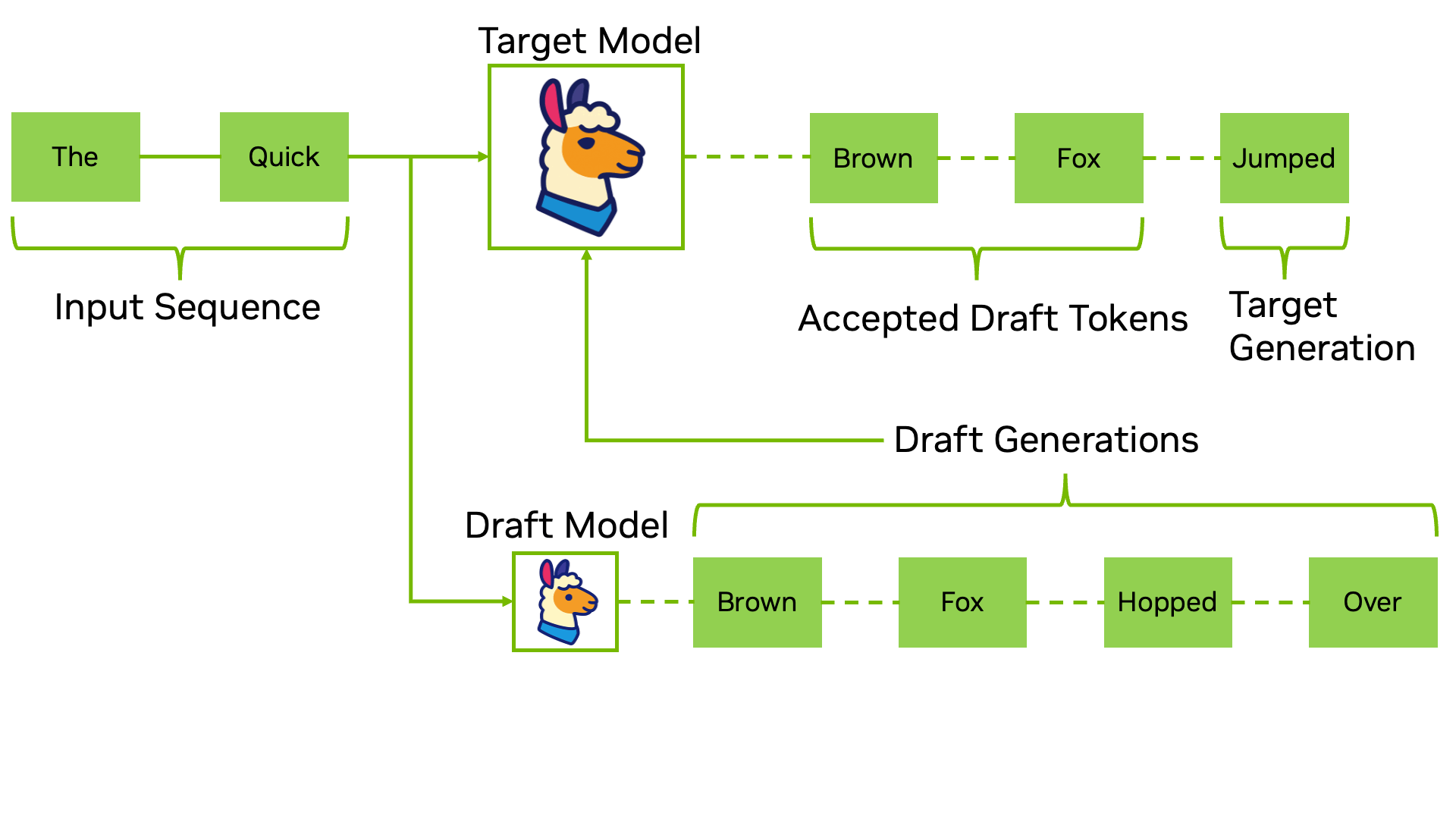
Verifying a token means trying to generate it by giving the complete sequence before this token as input to the Target model. When the Draft model proposes 5 tokens (“parked”, “near”, “the”, “main”, “street”), it creates a sort of batch input prefixes, as shown in the example below.
These input prefixes are then given to the Target Model as if they were independent, generating 1 token each. A token is verified if all the previous tokens match those generated by the Draft model.
In the example below, the 4th token (“main”) should be “restaurant”. As a consequence, the 3 tokens from the Draft model (“parked”, “near”, “the”) are verified and can be accepted in parallel.
The token “restaurant” can also be used as it was also generated by the Target model itself.
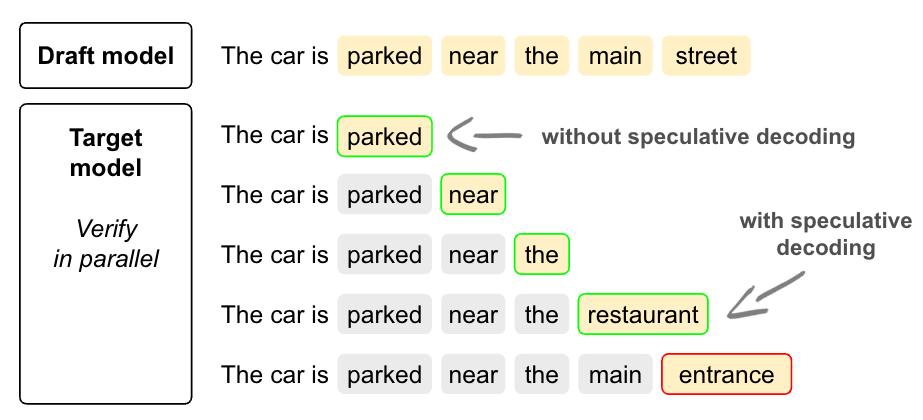
Example of speculative decoding process
As each verify step doesn't use much more memory transfer than a simple decoding of one token, validating several tokens at once allows for a healthy speedup if the draft model is fast and accurate enough.
What is EAGLE-3?
EAGLE-3 is a draft model for speculative decoding with a few specificities:
Input:
Usually, a draft model uses the same tokens as the target model as an input. In the case of EAGLE-3, it uses intermediate features of the target model instead. This requires a more complicated training pipeline, but allows for better accuracy.
Draft Tree:
EAGLE-3 reuse the draft tree introduced in EAGLE2. But EAGLE-3 doesn't just find a list of draft tokens, technically it searches for a tree of possible tokens. This helps select the best list of draft tokens, to maximize the overall acceptance length while minimizing the exploration of possibilities.
EAGLE-3 is one of the strongest speculative decoding approaches, delivering about a 3x speed-up on batch 1 inference while keeping a high accuracy for a relatively small model size and inference overhead. Its specificity is that instead of consuming text tokens, the draft model takes concatenated intermediate features of the target model as input. It can punch above its weight by reusing part of the "machinery" of the target model.
But there's no free lunch. Training requires generating (and often storing) those intermediate features per target model, so you end up with a model-specific EAGLE-3 and a non-trivial training you need to run for each target model. So it doesn't come as a surprise that the EAGLE-3 variants available today were trained at 2048 tokens context length while many LLMs nowadays have 100k+ token contexts.
We will focus below on EAGLE-3 limitations on context size but there are definitely more interesting details of EAGLE-3 in the original paper if you want to learn more. (Li, Y., Wei, F., Zhang, C., & Zhang, H. (2024). EAGLE-3: Scaling up Inference Acceleration of Large Language Models via Training-Time Test. arXiv preprint arXiv:2503.01840. https://arxiv.org/abs/2503.01840)
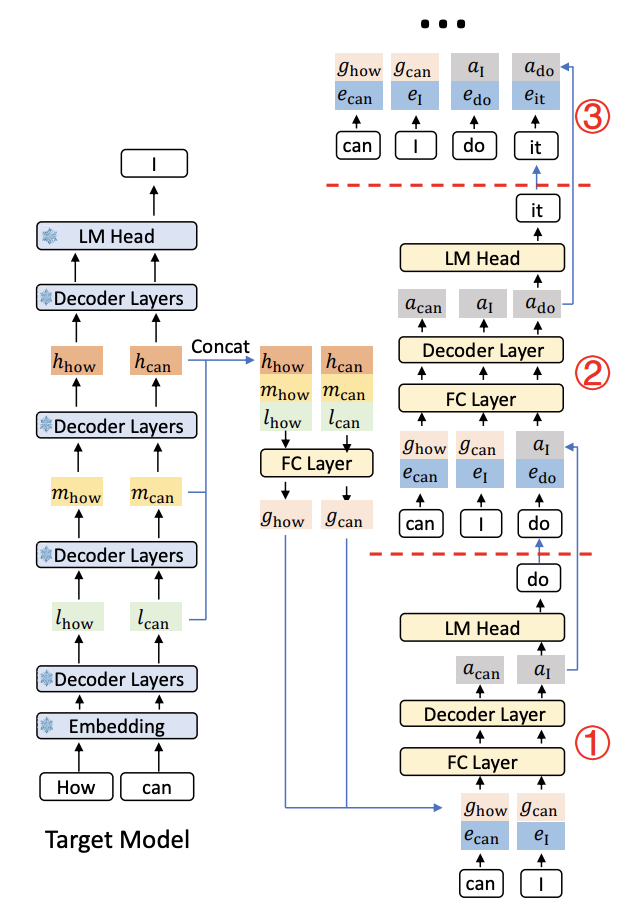
Diagram of the EAGLE-3 inference pipeline, illustrating the three steps of the draft model. l, m, and h, represent the low, middle, and high-level features of the target model, respectively. e denotes the embedding.
The Context Size Limitation
Despite EAGLE-3's impressive performance gains, it faces a critical limitation when dealing with long contexts:
1. Acceptance length degradation for long contexts
One of the main performance metrics of speculative decoding is the mean acceptance length, which is the average of accepted draft tokens at each step. The main issue with EAGLE-3 is that with contexts which exceed the max context size of EAGLE-3, there is a dramatically reduced acceptance length, leading to more rejections (see illustration below). Past a point, the overhead of running the Draft model exceeds the savings from accepted tokens, making this method counterproductive and potentially decreasing inference speed.
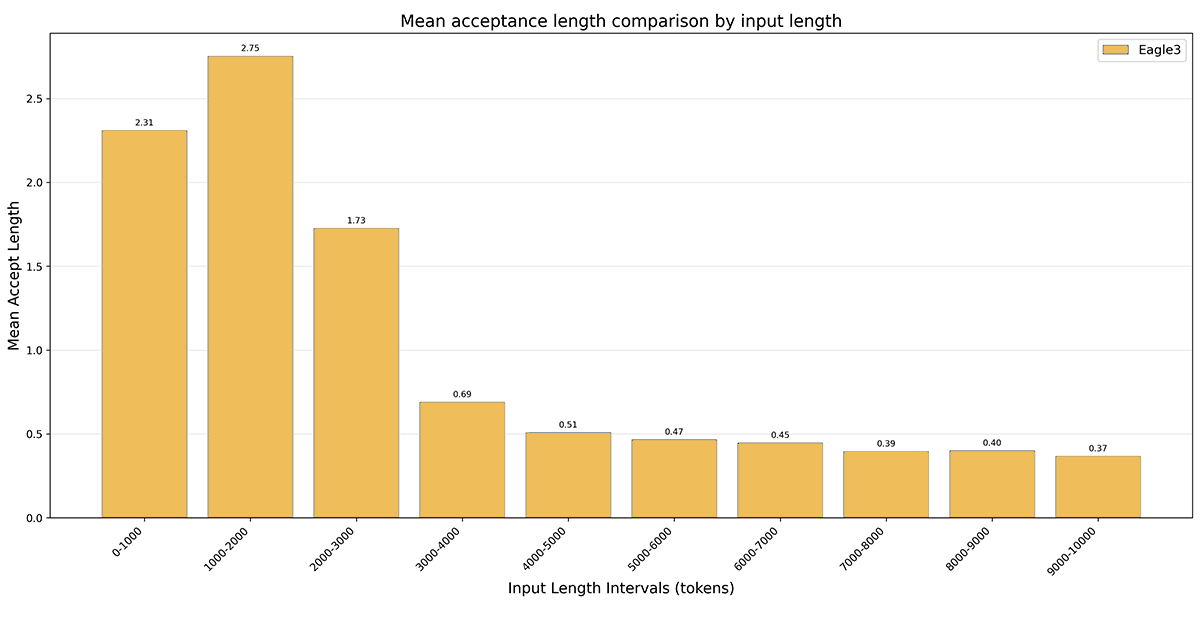
Example of Eagle-3 acceptance length for Llama-3-8b on a 5k-token context summarization task
The summarization task we used for our different tests was to summarize in a single paragraph different parts "of the book "Lost illusions", by Honoré de Balzac, in its English edition.
2. Stability issues
As EAGLE-3 has a max context length of 2048 tokens, besides the acceptance length degradation, long contexts can also lead to a lot of stability issues (depending on the implementation). The main issue is crashes due to unauthorized access to memory. It could be fixed by changing the implementation to use more memory. However, this wouldn't solve the important degradation in acceptance length, as it comes from more fundamental issues with its EAGLE-3 design and training.
With these limitations in mind, EAGLE-3 is most useful on very specific use cases where the context size is relatively small (<2,048 tokens), which makes it very limited to use in real case applications, where context sizes are often much larger.
Part 2: StreamingLLM - The Path to Unlimited Context
Understanding StreamingLLM
A method exists to compute an LLM with an unlimited context size, using windowed attention. It preserves a fixed number of recent KV pairs and discards older ones. Naive windowing hurts quality once context exceeds the window.
StreamingLLM addresses this core issue of Window Attention.
Core Innovation: Attention Sink
StreamingLLM innovation comes from a key observation: initial tokens accumulate disproportionate attention weights. Therefore, when a simple window attention is applied to the cache and the older keys/values are discarded, this significantly changes the result.
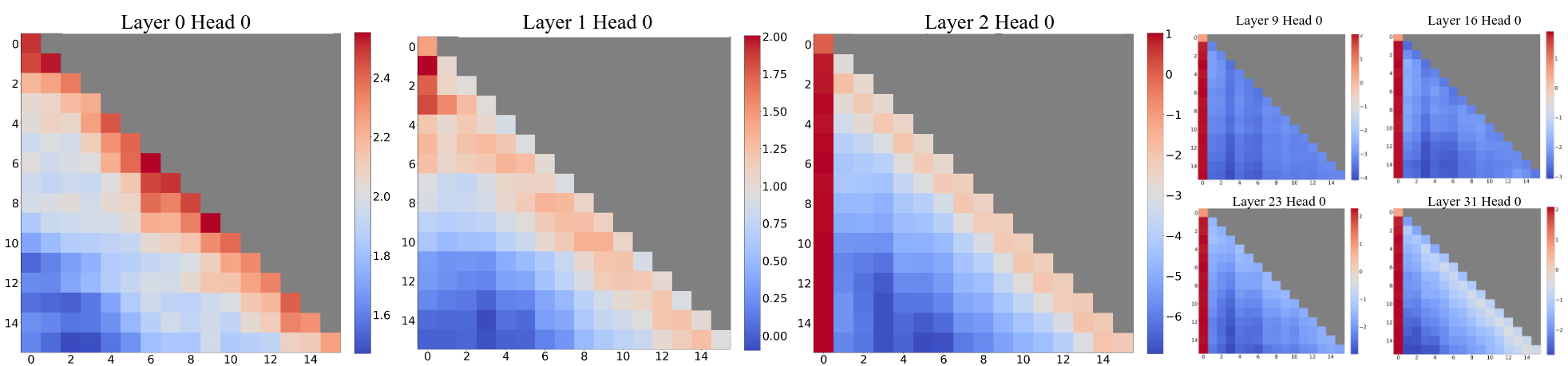
We can see from the StreamingLLM figure that the first token seems to have an especially strong weight.
The solution is implementing a window attention mechanism that keeps these first tokens (the attention sink), and to concatenate them to a standard window attention.
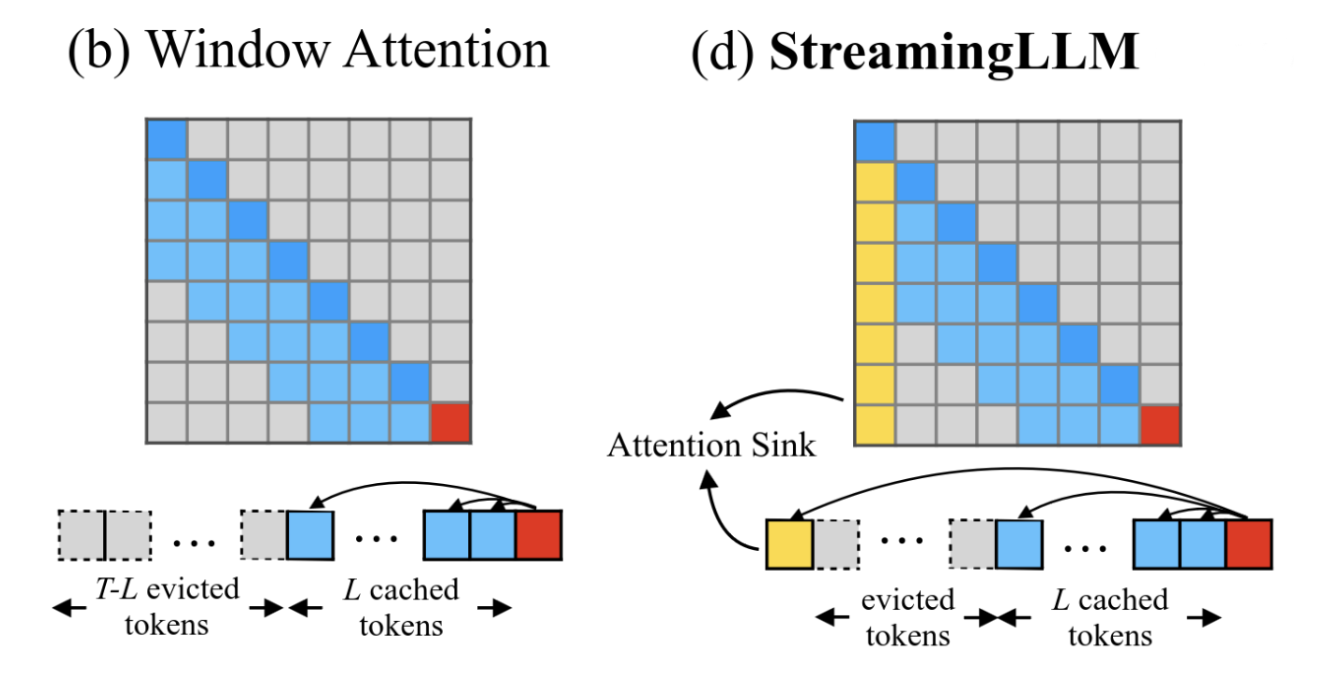
From StreamingLLM Paper: comparison between Window Attention and StreamingLLM
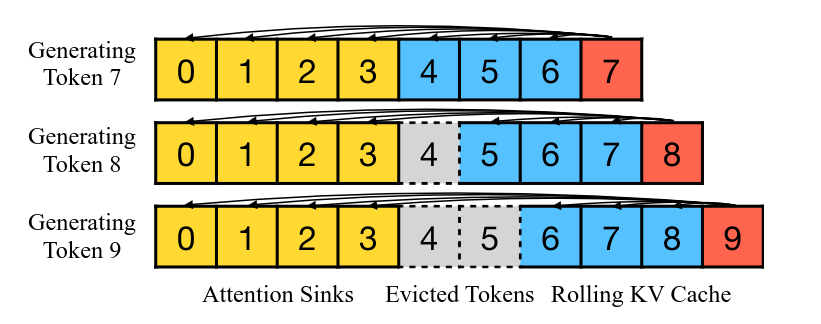
Rolling KV Cache Mechanism
The implementation of StreamingLLM is done using a rolling KV cache: the attention sinks are kept at a constant index in the KV cache, and each time a new token is added/evicted, the rest of the cache is rolled.
Position encoding
Usually, the position encoding is applied to the query and key tensors at the same time, and then the key tensors are stored in the KV cache with the position encoding already applied. However, in the case of StreamingLLM the position of a key tensor changes within the rolling KV cache as the older ones are evicted, so the position encoding cannot be stored along the key tensors in the KV cache.
To solve this, key tensors are stored without their encoding and the position encoding is recomputed at each step.
Limitation
One of the main limitations of Streaming-LLM is the lack of knowledge retention once the context length exceeds the window size, which limits its application on LLMs. It can generate texts for any size of input, but as it doesn't keep all of the knowledge the quality of the output can decrease a lot for long contexts.
Part 3: Introducing StreamingLLM-EAGLE-3 (SEAGLE) method
The vision: Leverage StreamingLLM to overcome EAGLE-3 context limitations
Our approach combines EAGLE-3's speculative decoding efficiency with Streaming-LLM's unlimited context capabilities, resulting in a speculative decoding system that is both fast and scalable. This solves the performance degradation problem of EAGLE-3 over long contexts.
By using StreamingLLM only on the Draft model, we are also not impacted by its knowledge retention limitation since the verification is done with the Target model on the full context.
1. Window size and sliding window
EAGLE differs with a classic LLM in that it has a tree attention. With this attention, the size of the context is augmented for each level of the tree, and the number of levels in the tree corresponds to the number of tokens we want the draft model to generate. With a proper sliding window, this would require changing the window position at each level of the tree. To make things a bit more efficient, we decided not to move the sliding window at every step of the Draft model, but to let its size increase at each level. If we want to decode 10 tokens during the draft phase, we can set the sliding window before the first step, while using a window size 10 tokens smaller than the context size we aim for.
For example, with EAGLE-3's maximum context size of 2,048 tokens, we set the sliding window at 2,038 tokens in total (counting the attention sink tokens) at the beginning.
By using this smaller number of tokens, we avoid evicting tokens from the cache at each decode step, which makes the process more efficient overall without affecting performance.
2. Prefill cropping
Each request starts with a prefill phase: first for the Target model, then for the Draft model. (EAGLE-3 uses intermediate layers from the Target model as inputs, which is why the Target must go first.)
However, because the Draft model evicts tokens from its cache once the context exceeds its window size, doing a full-context prefill doesn't make sense if that context is larger than the window. The tokens would just be dropped immediately on the first decode step.
We could implement any strategy to select the part of the context to keep in the cropped prefill. Our objective was obviously to try keeping the most relevant parts. Since the beginning of the context often contains important instructions, we kept this part.
That's why we decided to compute the prefill in two halves. The first half is the first "window size / 2" tokens, and the second one is the last "window size / 2" tokens. This way, the Draft model retains both part of the original task instructions and recent conversational context.
In the end this is only a minor enhancement specific to some cases. If we get a very long context in input with instructions longer than our 2048 window size, we wouldn't be able to keep all the instructions in context anyway.
Results
1. Performance on Long Contexts
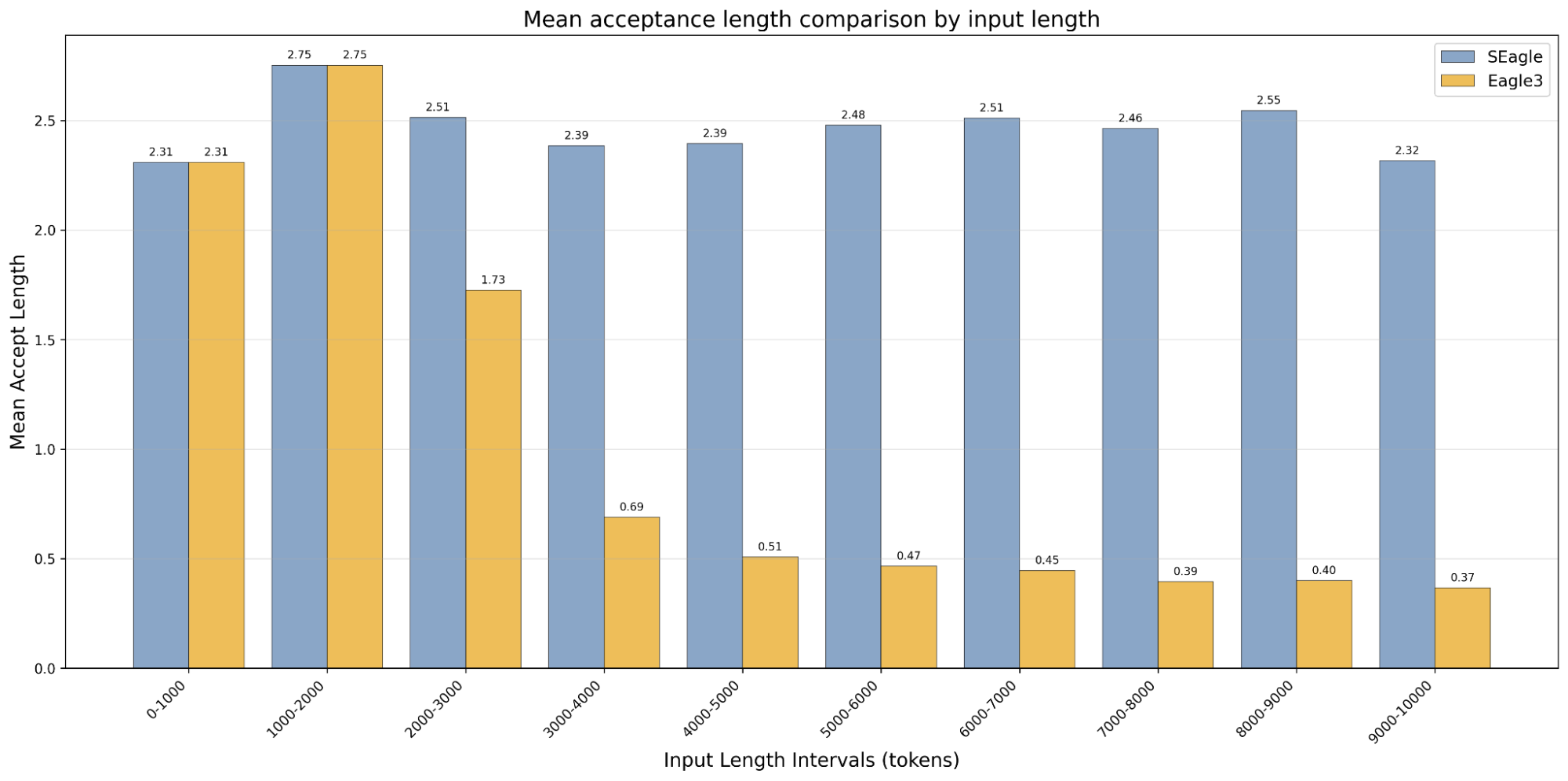
Result on the same summarize task we tested EAGLE-3 / Llama-3-8B
On summarization tasks with Llama-3-8B, SEAGLE maintains the same mean acceptance length as EAGLE-3 for short contexts (<2,048 tokens), but also remains stable up to 10K tokens with a mean acceptance length around 2.4. EAGLE-3's performance, by comparison, quickly degrades beyond 2K tokens with a mean acceptance length between 0.69 and 0.37 for context size between 3,000 and 10,000 tokens, roughly 4x lower than SEAGLE.
Based on those promising results, we ran others tests on longer contexts up to 32,500 tokens, to assess SEAGLE performance stability. As one can see in the results below, the mean acceptance length remained constant and even slightly increased.
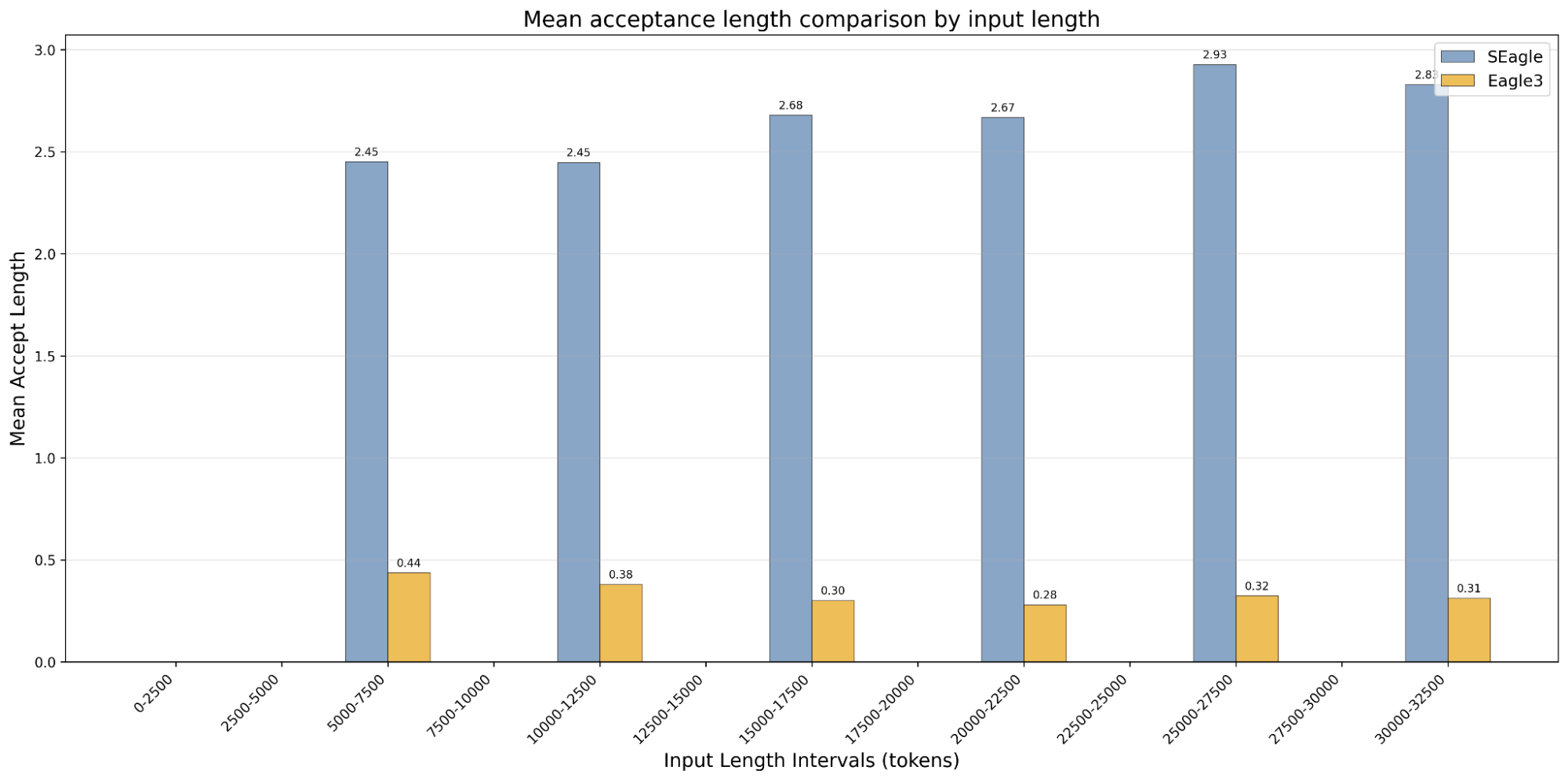
This tends to imply that using only recent context for the draft model is sufficient to ensure a good accuracy for speculative decoding. More tests could be done to check the differences between use cases, but at least we can know for sure that having access to the full context is not a universal prerequisite for good speculative decoding performance.
2. Speedup
For short contexts (below 2048 tokens), the mean acceptance length and speedup are exactly the same as EAGLE-3, as the algorithm is strictly identical. For longer contexts, a clear speedup appears, not only because the speculative decoding part is shorter to compute (with a fixed 2048 context instead of a growing one), but mainly because the greater acceptance length means that fewer validation steps are required.
Base model vs EAGLE-3 vs SEAGLE on a ~5000 tokens request
Another advantage of our method is also that the overhead is constant once the context size exceeds the window size. On the other hand, the overhead of EAGLE-3 continues to increase with the input size as its context is not limited.
3. Limits
Our implementation has been derived from the EAGLE-3 reference implementation. Although acceptance length shouldn't change much between implementations (as long as everything, like draft tree, is implemented), speedup can vary. It depends partly on the overhead of the speculative decoding inference.
Future Directions
Some further improvements could be done, concerning the method or the implementation. Some of the one we are:
1. Dynamic Attention Sink
- Learning optimal attention sinks
- Task-specific sink strategies
- Adaptive sink size optimization
2. Dynamic prefill crop
For long contexts, automatically select which part of the start and end of the context should be kept in order to maximize the performance of the draft model.
3. Hardware optimization
Custom GPU kernels for SEAGLE, integrating the rolling KV cache mechanism and the position encoding computation.
Conclusion
SEAGLE represents a step forward in LLM inference optimization and usability. By addressing both efficiency and scalability concerns, this hybrid approach enables new applications of speculative decoding inference acceleration that were previously impractical due to the context size constraint, like long document processing, extended conversations, code analysis or code generation.
This method also uses the existing trained models from EAGLE-3, which are already readily available for a lot of different models.
Our method demonstrates that the apparent trade-off between inference speed and context length is not fundamental, we can achieve both efficient inference and long context handling.
If you're interested in improving speculative decoding methods and using SEAGLE to speed up your inference on long context use cases with inference engines, like vLLM or SGLang, let us know. We're open for collaboration! (contacts@withexxa.com).
Our code is available on our github repository: https://github.com/withexxa/SEAGLE_public
References
[1] Li, Y., Wei, F., Zhang, C., & Zhang, H. (2024). EAGLE: Speculative Sampling Requires Rethinking Feature Uncertainty. arXiv preprint arXiv:2401.15077. https://arxiv.org/abs/2401.15077
[2] Li, Y., Wei, F., Zhang, C., & Zhang, H. (2024). EAGLE-2: Faster Inference of Language Models with Dynamic Draft Trees. arXiv preprint arXiv:2406.16858. https://arxiv.org/abs/2406.16858
[3] Li, Y., Wei, F., Zhang, C., & Zhang, H. (2024). EAGLE-3: Scaling up Inference Acceleration of Large Language Models via Training-Time Test. arXiv preprint arXiv:2503.01840. https://arxiv.org/abs/2503.01840
[4] Xiao, G., Tian, Y., Chen, B., Han, S., & Lewis, M. (2023). Efficient Streaming Language Models with Attention Sinks. arXiv preprint arXiv:2309.17453. https://arxiv.org/abs/2309.17453
[5] Chen, C., Borgeaud, S., Irving, G., Lespiau, J. B., Sifre, L., & Jumper, J. (2023). Accelerating Large Language Model Decoding with Speculative Sampling. arXiv preprint arXiv:2302.01318. https://arxiv.org/abs/2302.01318