What is prompt caching?
Prompt caching allows you to store large portions of your prompts, such as background information, instructions, or example outputs, and reuse them across multiple API calls. This feature is particularly beneficial for applications that require consistent context or extensive background knowledge.
When to use prompt caching?
Prompt caching is useful in many scenarios, particularly:
- Large documents processing and analysis
- Contextual retrieval to improve performance on RAG applications
How it work?
Prompt caching is automatically applied to all your requests within the same batch. We automatically detect if part of a request can be cached and reused for other requests. We manage it in two steps:
- Cache writing: When you first send a prompt with cacheable content, EXXA stores it in the cache.
- Cache reading: Subsequent API calls within the same batch can reference the cached content, reducing the amount of data to be processed.
Pricing
The main advantage of prompt caching is that it allows you to reduce the costs of requests sharing the same context. Here are the pricing details:
- Cache writing: Same price as the base input token price for the model
- Cache reading: 80% cheaper than the base output token price for the model
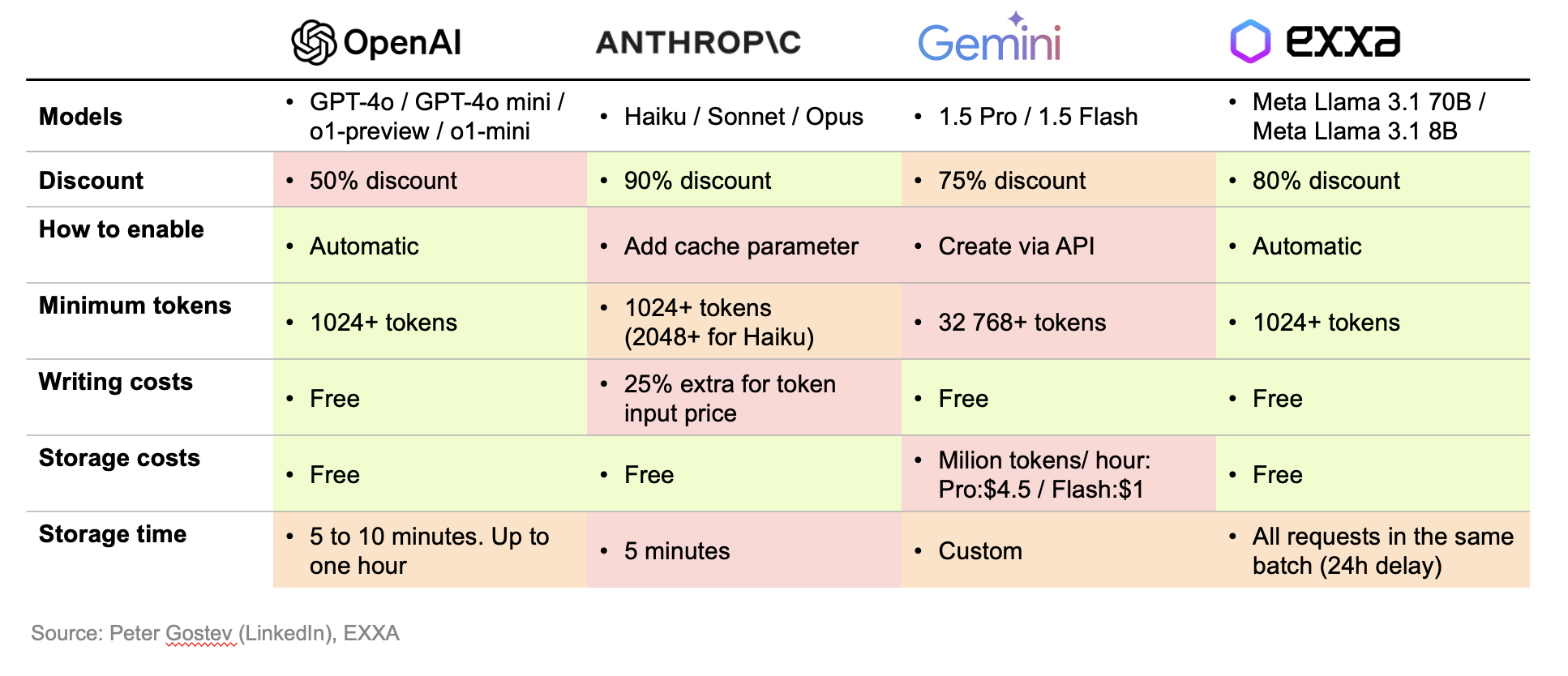
How we compare with other providers
Start using it today!
To start using prompt caching, you need to:
- Structure your prompt with static content at the beginning of the prompt and variable content at the end.
- Ensure your prompts meet the minimum token requirement for caching (1024 tokens)
- Use our API as usual – caching is applied automatically when applicable.